STRUCTURE, ORGANIZATION AND FUNCTION OF GENES
STRUCTURE
A molecule of DNA or deoxyribonucleic acid consists of two complementary chains twisted clockwise about each other in the form of a double helix - " the twisted rope ladder " model, proposed by Watson and Crick. Each chain is composed of a series of nucleotides, each of which is composed of a sugar - deoxyribose, a phosphate and a purine or pyrimidene base. The bases are either one of the two purine bases adenine (A) or guanine (G), or the two pyrimidene bases thymine (T) or cytosine (C). Fig. 1.
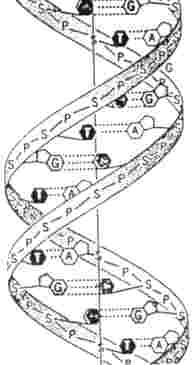
Fig 1
The "sides" of the ladder are made of deoxyribose sugar residues linked alternately to phosphates by strong phosphodiester bonds at the 3' (three prime) and 5' positions of each sugar. The "rungs" of the ladder are made of a random order of purine and pyrimidene bases, each projecting from the 1' position of the deoxyribose residues of each chain in the direction of the other chain. Fig. 2.
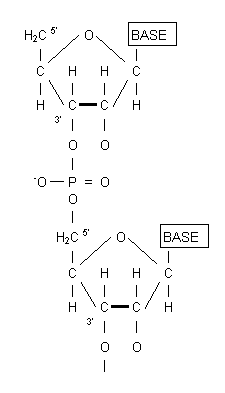
Fig 2
These bases are joined across the gap between the two chains, held together by weak, vaccilating hydrogen bonds. The pairing is not random with any other base, but in a specific pattern where the adenine of one chain pairs with a thymine of the other chain (A - T) using two hydrogen bonds or the guanine of one always with a cytosine of the other (G - C) using three hydrogen bonds. The two chains thus complement each other. Fig. 3.
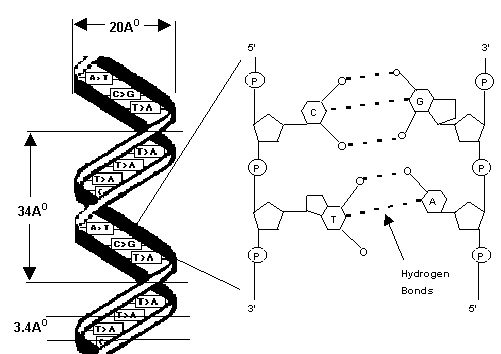
Fig 3
The dimensions of the DNA molecule are shown in fig. 3. A human diploid somatic cell nucleus has a length of DNA equal to nearly 2 metres. This length is carried in 46 chromosomes. Genes are definite varying lengths of this long strand of DNA.
The relationship of genes to DNA can be easily understood if one remembers the phrase, " Genes are to DNA, what words are to a sentence". Like words they are of varying lengths and spaced out. As for its composition, a gene is a series of nucleotides or a series of phosphate - sugar - base complexes.
There are an estimated 100,000 structural genes in a single human somatic cell, which account for only half the length of the total DNA. The balance DNA consist of moderately repetitive or highly repetitive DNA, which as the name implies consists of DNA which repeats itself at a moderate or excessive frequency. The lengths of genes are measured in kilobases (kb) or megabases (Mb). For example a 15 kilobase gene will have 15,000 base pairs. To understand this, the following units must be familiar.
A unit length of DNA - One base pair (A - T) or (G - C)
1000 base pairs - One kilobase (kb)
1,000 000 base pairs - One megabase (Mb)
Ribonucleic acid or RNA differs in structure from DNA in several respects:
- It has the sugar ribose, instead of deoxyribose.
- The pyrimidene base uracil (U) replaces thymine (T), so that the correlating purine and pyrimidene bases are (A - U) and (G - C).
- It is single stranded.
- There are five types in humans, compared to only one of DNA.
There are two classes of DNA:
- Unique sequence (nonrepetitive) DNA.
Contains sequences that code for mRNA. Genes are comprised of unique sequence DNA that occur once in the genome and encodes information for RNA and protein synthesis. They make up only 10% of DNA. - Repetitive DNA.
Contains sequences which are repeated excessively (300,000 to 900,000 times) and called the highly repetitive type, and those repeated at a lesser frequency of 50,000 to 100.000 times), referred to as the moderately repetitive type. The repetitive DNA make up a major portion of the balance of the total DNA.
ORGANISATION OF GENES
Exons are the functional portions of gene sequences that code for proteins. Introns are the noncoding DNA sequences of unknown function that interrupt most genes. The number and size of introns vary in different genes. Fig. 4 shows the typical structure of a human gene.
Exon - Functional gene.
Intron - Noncoding regions.
GT - First two bases at the 5' end of each intron.
AG - Last two bases of each intron.
ATG - The universal translation initiation codon, at 5' end of gene.
TATA box - Help direct important enzymes to initiation site. 20 - 30 bases
to the left.
CCAAT box - Regulates transcription, a further 50 - 60 bases upstream.
TAA,TAG,TGA - One of these three termination codons terminates transcription.
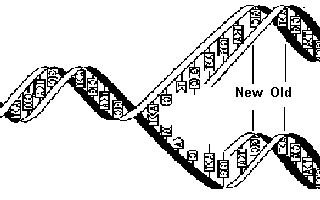
Fig 4
MITOCHONDRIAL GENES
Mitochondria are the only organelles outside the nucleus that have their own DNA in the form of 2 - 10 copies of circular double stranded DNA measuring about 16 kilobases in length. Fig. 5. It codes for 13 proteins which are components of the mitochondrial respiratory chain and oxidative phosphorylation system as well as 2 rRNAs and 22 tRNAs. Mitochondrial DNA (mt-DNA) differs from nuclear DNA in that :
- It is circular rather than linear.
- It consists of mostly unique sequence DNA, rather than repetitive DNA.
- It has a slightly different genetic code.
- It is exclusively transmitted to the next generation by mothers.
- It uses the triplet TGA to code for tryptophan, rather than a stop codon as seen in nuclear DNA.
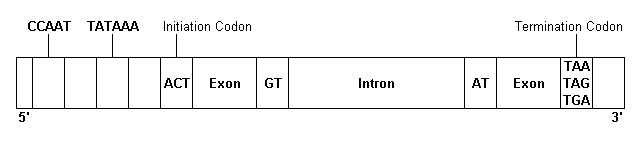
Fig 5
FUNCTIONS
Immediately before cell division, be it mitosis or meiosis I, the DNA content of the parent cell is doubled, resulting in two new complementary strands formed according to the rules of base pairing. Fig. 6. This is called semiconservative replication, where each separated strand or template acts as the mould for the development of a new one.
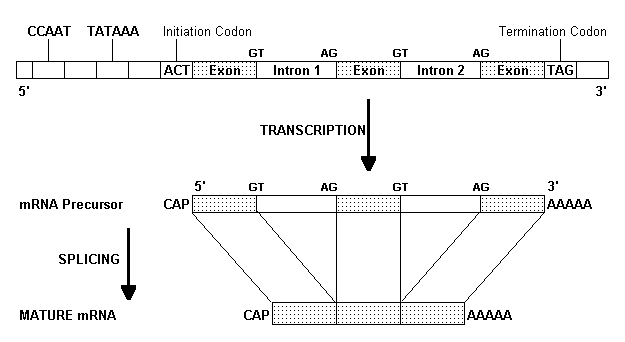
Fig 6
Less than 10% of DNA act as a template for the production of messenger RNA (mRNA), a process called transcription. This mRNA leaves the nucleus, enters the cytoplasm and translates into amino acids, the "building blocks" of protein. Translation is the next stage in protein synthesis. This takes place in the cytoplasm and on the ribosome. The function of genes therefore is to produce proteins.
PROTEIN SYNTHESIS
The first stage is that of transcription where a strand of mRNA is synthesised from the original coding strand of DNA, within the nucleus. The two strands of the DNA serve as separate templates for transcription. For this the ATG, TATAAA and CCAAT sites are important. Fig 7. The original large strand of RNA synthesised is called a primary transcript which is made up of introns and exons of the gene and is very unstable. The addition of a cap structure to the 5' end and a string of adenylic acid (poly A) residues to the 3' end stabilises it. The poly A sequence in addition acts as a stop signal to terminate transcription. The introns are then removed, the exons spliced (pasted) together and the mature mRNA is released, to be transported to the cytoplasm for translation.
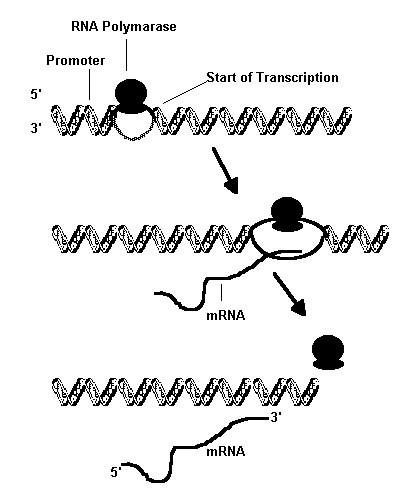
Fig 7
Translation is the process that converts the mRNA sequence derived from the coding strand of DNA in the nucleus into the sequence of amino acids that form a protein. Fig 8.This process occurs on ribosomes in the cytoplasm of the cell in a 5' to 3' direction.
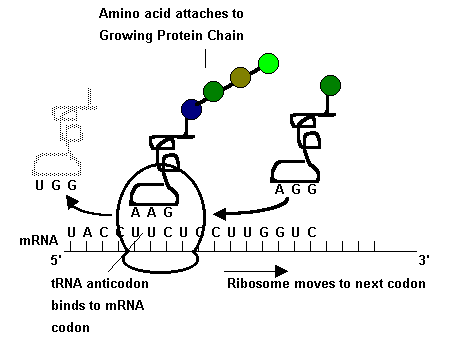
Fig 8
Each of the 20 naturally occurring amino acids in the cytoplasm
have three bases assigned as its code from a selection of combinations
derived from the four bases A,G,U and C. This means that 64 possible combination
triplet or three base codes (codons) will be available for the 20 amino
acids. Table 1.
Transfer RNA (tRNA) are molecules that attach to individual amino acids and bring them to the mRNA - ribosome complex. The mRNA now moves over the ribosome bringing successive triplet bases into position allowing the amino acids coded by these three base codes to be brought in by the tRNA in an ordered sequence determined earlier by the parent DNA. Three of the 64 codons, namely UAA, UGA and UAG are termed termination codons, which when encountered in translation, stops the addition of any more amino acids, separates the tRNA from the ribosome and releases the peptide. Fig. 8.
Amino acids are therefore joined up with peptide bonds in
a definite series determined by the gene, to produce a protein. Most amino
acids are coded by more than one codon or triplet which makes the code
degenerate or too non specific. Table 1.
|
|
|||||
|
|
|
|
|
|
|
|
|
Phe Leu Leu |
Ser Ser Ser |
Tyr STOP STOP |
Cys STOP Trp |
C A G |
|
|
Leu Leu Leu |
Pro Pro Pro |
His Gin Gin |
Arg Arg Arg |
C A G |
|
|
Ile Ile Met |
Thr Thr Thr |
Asn Lys Lys |
Ser Arg Arg |
C A G |
|
|
Val Val Val |
Ala Ala Ala |
Asp Glu Glu |
Gly Gly Gly |
C A G |
|
Amino Acid Abbreviations: Ala=alanine;Arg=arginine;Asn=asparagine;Asp=aspartic acid; Cys=cysteine; Gin=glutamine Glu=glutamic acid;Gly=glycine;His=histidine;Ile=isoleucine;Leu=leucine;Lys=lysine; Met=methionine;Phe=phenylalanine;Pro=proline;Ser=serine;Thr=threonine;Trp=tryptophan; Tyr=Tyrosine; Val=valine |
|||||
Table 1
Some proteins after translation are further modified to become active. Fig. 9. For example the initial protein product in insulin synthesis is an 82 amino acid product called proinsulin which next loses 31 amino acids to become the active hormone. During protein synthesis, the primary structure, which is the simple sequence of amino acids, changes to a twisted secondary structure due to bonding between different peptides. The final product is a tertiary structure which is three - dimensional and has the most favourable arrangement of polypeptide chains for efficient and optimal activity.
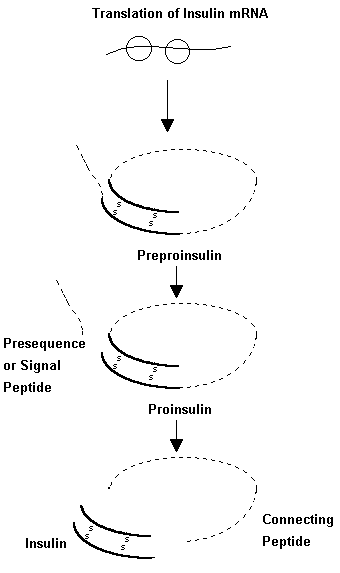
Fig 9
All cells of the human body have genes or DNA that code for all cellular functions. The product of a gene may be a structural protein, a hormone, an enzyme or an important component of a metabolic pathway. Yet, cells are specialised with specific functions only due to differential expression of different genes. For example, the cells of the thyroid gland have the genes for insulin but do not produce it in the thyroid as it is in a state of repression (Inactivity) by a process called methylation. In the cells of the islets of Langerhans however the gene remains active or nonmethylated.
Gene disorders like phenylketonuria were diagnosed by detecting a reduced level of the enzyme phenylalanine hydroxylase in blood. With the progress of technology, it is now possible using recombinant DNA technology to investigate and diagnose such disorders at the level of the DNA strand in the short arm of chromosome 12.